Center Leo Apostel
Krijgskundestraat 46
1050 Brussel
jbollen@vnet3.vub.ac.be
Hypertext networks are in many ways highly similar to human long term memory, structurally as well functionally. Both hypertext networks and human long term memory store information by coding its meaning in a distributed network of relations between semantic sub-components. Both are used and browsed for retrieval in similar ways. The results from psychological research concerning the relationship between the complexity of stored items and the speed with which they are recovered from human long term memory, might aid in understanding why certain hypertext networks perform better than others.
1.1)Storage in human long term memory.
Most models of human information storage adhere to what is called `the principle of component coding' [Klimesch, 1994] [Hinton, 1981] i.e. that a concept's meaning in human memory is distributively coded as the relations and connections between its semantic sub-components. In this view, storage of information takes place by decomposing concepts into certain semantic subcomponents and connecting these to the already established network of concepts in memory. The meaning of the word `chaos' could e.g. be stored by connecting the word and several of its associated meanings (sub-components), such as `irregular', `out of control' and `high entropy', to the already existing network. `Chaos' would thereby not just be defined by its subcomponents acting like subsumed descriptors of its meaning, but rather by these sub-concept's relations among themselves and other parts of the memory network.
After absorbing new knowledge into the network of subconcepts, cue-based retrieval mechanisms will be able to adequately retrieve information from the network when supplied with incomplete and noisy requests. The amount and quality of provided contextual data can often be more important than precision and exact descriptions [Mc Clelland & Rumelhart, 1986]. The previously mentioned sub-concept `out of control' could e.g. be connected to the concept `child', while the sub-concept `irregular' might be subsumed in the network nodes regarding `groups'. Afterwards, when the memory network is confronted with a group of school children on the loose it could very well retrieve the concept `chaos'.
1.2) Hypertext networks.
Traditional media like films, books and television broadcasts do not seem not to be taking full advantage of the intelligence and flexibility with which people in general deal with information. While human subjects process, store and retrieve information in an highly interactive, associative and distributed manner, most man-made databases and systems of information processing (books, encyclopaedia, dictionaries, films, etc...) operate strictly linearly and uni-directionally. Information is presented as a one-dimensional stream of data (e.g. film) with the receiving end (i.e. listeners, readers, audience) being passive and having only very limited means of intervention. Data stored in databases, libraries, encyclopaedia is mostly organised in a strictly linear format and accessed through lexical or alphabetical indexes.
The format of most contemporary media thus seems to be basically incompatible with the way in which we naturally deal with information. These precise considerations lead to the famous [Bush, 1945]"As we may think" paper in which the basic principles of hypertext and its possible benefits were put forward. Hypertext was conceived as a flexible, non-linear system of information storage and retrieval that could possibly be more compatible with human information processing.
Hypertext systems typically consist of a group of linked texts. Texts within the network contain linked items, that refer users or browsers to other relevant pages. E.g., a page explaining the details of evolution theory could contain the sentence `natural selection' and have these words refer to an essay on Darwin's life and work. This page could in its turn refers to a map of the Galapagos islands. Hypertext users looking up information on Darwin could begin their search by consulting the pages on natural evolution and from there on find out Darwin conducted much of his work at the Galapagos islands.
The World Wide Web is an excellent example of how hypertext systems can store huge amounts of information of previously unknown content or structure. The World Wide Web is such a huge, world-wide hypertext network. Internet servers store hypertext pages, that can globally refer to any other text in the network. User can look up information stored on any machine or text within the network by simply selecting the appropriate hyperlinks within the pages they consult. The World Wide Web presently contains millions of hypertext documents which are being consulted by thousands of users daily.
1.3) Storage in hypertext networks.
Hypertext, according to its intended principles of operation, shares many of its features with human long term memory [Jonassen, 1990]. If one assumes texts within such network to convey certain specific concepts and their meaning, then words and sentences within the text can be seen as semantic sub-components of the text's `meaning'. These subcomponents of the text's meaning can be linked to other texts that can in their turn link to other texts. Hypertext networks can thus be regarded as distributed memory networks that store meaning above the level of individual nodes by associating text items (subcomponents of meaning) with other text items, etc...
An example could clarify this position. Imagine an instructional hypertext network offering information on combustion engines. A start page could introduce the readers to the basics of engines, i.e. the meaning of the concept `combustion engine'. This page would provide links from words such as `pistons', `ignition', `carburettor', etc to texts that clarify these concepts' meaning. The relations between these subsumed semantic sub-components would as such code the meaning of the concept `combustion engine'. This concept, in its entirety, could in its turn be connected to an even larger network explaining the meaning of the words `automobile' and `modern transport' by connecting its subcomponents (`pistons', etc.) to the other already installed pieces of the bigger network.
(Although the previous example might imply hypertext pages' meaning to be decomposed in strictly hierarchical networks that spread out to more and more pages, explaining or representing ever finer details, this need not necessarily be the case. Like human memory, hypertext is not supposed to be organised according to strict hierarchical principles. Subconcepts can refer to other subconcepts on the same level of detail, connections can easily skip several hierarchical layers, etc. The network could in fact be entirely self-referential.)
From a structural perspective hypertext networks do indeed remarkably well resemble the structure of human long term memory. Since the nature of information retrieval strategies is largely determined by a memory's underlying coding format, hypertext and human long term memory's resemblance in coding format and structure will result in highly similar retrieval behaviour.
2.1) Complexity.
Intuitively, many people feel that certain concepts are more complex than others and that retrieval of these concepts demands more energy and time from human memory than would be expected for simple, uncomplicated ideas. The hypothesis that was put forward to explain these findings is commonly referred to as the `complexity hypothesis'[Gentner, 1981]. Complex memory items contain more references and subcomponents that retrieval mechanism must search through in order to retrieve the appropriate memory. Simpler memory items contain less subcomponents and references and can thus be retrieved faster.
2.2) Connectivity.
It is however also commonly understood that especially well-established memories that years of experience and learning have enriched with many intricate details and connections are most easily retrieved from human memory. These memory items are part of everyone's natural knowledge required for daily life, so fast retrieval is of utmost importance. They are however well extended and complex items. Could then be concluded that complex memory items are easier to retrieve than less complex items? [Klimesch, 1994] have indeed shown that human subjects when asked to evaluate over-learned, complex memory items responded faster than when being confronted with simpler, less complex items. This is what researchers refer to as the `Connectivity hypothesis': complex memory items having more subcomponents and better connections to other concepts are more easily activated and retrieved, because searches in memory are more probable to be referred to well-connected and linked items than items that are not.
2.3) Coding.
Both Connectivity and Complexity hypothesis have been demonstrated in an experimental setting, and the question remains how these contradictory findings could be explained. One hypothesis could be that both effects do indeed seem to occur, but in highly different circumstances. The processes involved in the retrieval of well-established, over-learned memory seem to be different from those involved in the retrieval of newly learned items.
Coding of information might be an important factor. Overlearned items have, in the process of learning and repeated retrieval, had sufficient opportunity to be deeply integrated into the existing memory network. These memories' sub-components can be expected to be well connected to many other parts of the network, and to be well connected among themselves as well. Retrieval mechanisms can in this case make extensive use of the connections between the different memory items. [Kroll&Klimesch, 1992]
2.4) Spreading Activation.
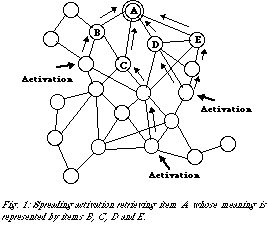
Automatic spreading activation (ASA) could very well be one of these retrieval mechanism [Anderson, 1983]. ASA is presumed to retrieve information from memory by activating specific items in memory. After the initial activation of a number of well-chosen network nodes, activation will simultaneously spread out to other nodes, using the connections and links that exist between associated memory items in parallel (fig. 1). Memory items that are directly or indirectly referred to from activated items will pass on activation to other associated items and so on. The retrieval process stops and concludes its search when certain items accumulate enough activation to be retrieved from memory.
The primarily activated items are chosen so that they are most probable to be associated with the required information. Their activation cues the memory network as to what information is to be retrieved. One could for example imagine that in order to make someone retrieve a friend's name, that person is confronted with specific cues such as `tall', `brown hair' and `loud'.
ASA is supposed to be extremely fast. First, because it is not dependent upon the limited capacity of conscious information processing channels. After being cued, activation spreads out automatically through all available connections in memory and is no longer monitored by the slow and explicitly functioning mechanism of conscious processing. Secondly, ASA uses many connections and nodes in parallel, so its efficiency and speed is not linearly dependent upon the number of items to be searched.
2.5) Limitations of retrieval by spreading activation.
The general quality of the network ASA is operating upon, however can be a determining and limiting factor. The automatic spreading of activation is bounded by the number and quality of available connections. Items that have only few incoming connections might not be able to accumulate enough activation to be retrieved. Certain parts of the network might even be unreachable because of insufficient direct and indirect connections. For an item to be retrieved it must be well integrated into the memory network which in its turn will only support efficient retrieval if its overall structure is well organised and connected.
Memory items for which this condition has not been satisfied will have to be retrieved using different strategies that do not depend upon overall network connectivity.
Superficially processed and learned concepts might not have been thoroughly integrated into the memory network. While over-learned concepts are defined by their subcomponents' relation to each other and other parts of the memory network, these concepts rely entirely on their subcomponents. Meaning is expressed in the nature of directly subsumed subcomponents, connected in more or less isolated, hierarchical fan-like structures, rather than the structure of its connections to other parts of the network.
2.6) Explicit Searches.
Retrieval strategies, like ASA, that depend on the connections between a concept and its `semantic' environment in memory, will experience difficulties retrieving these concepts. Rather than relying on a specific item's connections in memory, retrieval mechanisms will have to depend upon conscious and linear searches through memory.
One could imagine searches e.g. that retrieve information by linearly searching through all of a certain concept's features and matching them one by one to the features of whatever is being looked for.
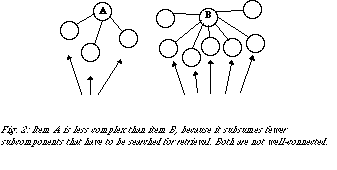
Since the processing capacity involved in explicitly comparing and analysing the different sub-components of a specific concept's meaning is limited, the speed with which these searches can retrieve information is dependent upon the number of items to be searched.(fig. 2) Consequently complex items whose meaning is coded by many sub-items will require more time and effort to retrieve.
- individual browsing
- global characteristics of collective browsing,
which each correspond to the complexity and connectivity hypothesis respectively.
3.1) Individual browsing:
Hypertext networks are designed to be browsed, a process that enables users to determine their own path through the network of linked texts, images, sounds and movies. Browsing can be thought of as a semi-goal oriented activity, wherein users try to locate more or less specific information by positioning themselves at a certain location in the network and using the connections provided in the hypertext pages to migrate towards the information they were looking for. [Catledge&Pitkow, 1995] have shown that browsing by users that did not a priori know the exact location of information in the network is indeed by far the most applied method of retrieval for the WWW (51% of activity). The reported data shows that a majority of WWW users does not use URL's, indexes, etc. to retrieve information but rather traverses hypertext connections according to some search heuristic.
Although a majority of browsers do not (and can not) know the exact position or nature of the network items they are looking for in advance, browsing is in essence a goal-directed activity. A number of researchers have identified several types of browsing activity, most of which can be organised according to differing levels of presumed "goal-directedness". [Canter et al, 1985] identify 5 types of browsing strategies: scanning, browsing, searching, exploring and wandering, of which specifically browsing and searching are concerned with retrieving a certain piece of information from the hypertext network. [Cove&Walsh,1988] distinguish three types of browsing strategies: search browsing, general purpose browsing, and serendipitous browsing (purely random activity). This distinction introduces a spectrum of strategies ranging from highly goal-oriented retrieval strategies to purely random browsing activity.
The categorisation of browsing styles can help in understanding the general characteristics of the man-hypertext-system and might provide general guide-lines to hypertext designers as [Catledge&Pitkow, 1995] suggest. However, modelling and controlling the precise cognitive processes involved in retrieving information from hypertext networks might prove to be at least as important.
3.1.1) Lost in Cyberspace.
Although browsing might be the most applied method of retrieval, it can be highly problematic. A number of researchers identify several possible `limitations to the usefulness of hypertext', all of which are due to the cognitive demands placed on the designers as well as users of hypertext systems.[Conklin, 1987] mentions the user-associated problems of `disorientation' (getting lost in space, loosing track of one's position in hypertext) and `cognitive overhead' (the difficulty of deciding `where to go next' and choosing and rejecting alternative links and paths). A detailed analysis of the precise processes involved in goal-directed browsing will help to better understand and control these problems.
3.1.2) Analysis of hypertext systems.
The characteristics of the system within which browsers operate shape the browsers behaviour as much as his own intentions, strategies or goals. Hypertext systems can functionally be analysed into three components:
1) the hypertext network
2) the interface and
3) the user.
Hypertext networks consist of an interconnected set of nodes, whose structure can be represented by a binary n x n matrix M, in which the value of each element cij indicates whether a connection between the nodes i and j is present or not. As such, the values of each column i of matrix M code the hyperlinks from network element i to all other nodes in the network.
Within the hypertext system the interface mediates between the user and the hypertext network. The interface makes visible the network by translating its content into a readable and browsable format. This format can be entirely text based, as is the case in the UNIX Lynx browser, but can also be very complex using graphics, windows and objects. In the World Wide Web's case for example, the Netscape browser downloads pages from any particular server and then translates them to a certain graphical format in which hyperlinks are marked using colours and underlining. Images, buttons and moving images can be incorporated into the pages and they can be marked as hyperlinks as well.
The user or browser is charged with reading the presented pages the interface provides and reacting according to his/her insights by selecting specific hyperlinks. Clearly, random, recreational browsing that can only be defined by the absence of any goal or strategic consideration in the user will be extremely difficult to model. If browsers, on the other hand, goal-directedly search for information from hypertext networks a number of plausible models can however be postulated.
3.1.3) Hill-climbing as a model for retrieval from hypertext networks.
The problem that the browser in search of relevant information is confronted with when browsing through hypertext networks, is that of locating information whose nature nor exact position is known in advance. Nor can the user, especially in the case of large networks, make use of precise information concerning the structure of the hypertext network within which the desired information is embedded.
In fact, disregarding possible previous experiences with a specific hypertext network, the only information available to browsers is the present page and its links to other pages. This strictly local information could however be sufficient for the user to apply a specific kind of tuning heuristic known as `hill-climbing'. [Schildt,1987] Hill-climbing is known as a heuristic strategy that tries to optimise a certain function by iteratively changing position towards the local maximum value. From any position, hill-climbing chooses its next position so that it heads in the direction of the highest slope. It is named after the strategy hikers use to locate the peak of a mountain by always moving in the direction of the highest slope.
For hypertext networks, this strategy involves the user evaluating the different alternatives provided in the page he is reading by assessing their possible semantical distance to the desired location in the network. The hyperlink that is most likely to decrease the associative distance between the browser's present position in the network and the desired information, will be chosen. If this simple rule is repeatedly applied, the browser can expect to gradually move closer and closer to possibly relevant information within the network.
How do browsers assess the semantical distance between a certain linked item and the information they wish to retrieve from the network? One has to assume browsers might not be fully aware of the exact content or position of the desired information, but can nevertheless make use of the knowledge they already have concerning the semantic surrounding of a certain concept or idea [Snowberry et al., 1985]. If , for example, a browser needs to retrieve a hypertext page discussing the details of `bicycle transmission chains', he will know the concept `bicycle' is in general associatively related to other concepts such as `wheels', `traffic', `Holland' or even `environment'. He will also be able to asses to what extent these concepts are related to `bicycle' (`Holland' less than `wheels') and when confronted by any of these concepts in a hypertext network he will know whether he is moving closer or further from what he is looking for.
In fact, one could assume that browsers, inspired by their general or natural knowledge of the world, could be capable of assessing the strength of relationship between any pair of nodes in the hypertext network. This associative knowledge can be represented by a n x n matrix W, of the same size as the one representing the connections within the hypertext network. The continuous elements of the matrix aij would represent the strength of association between the two network nodes i and j according to the browser's judgement. Matrix W would as such be a subset of the browser's already existing general knowledge of associations.
Goal directed browsing behaviour can then be mathematically modelled as the following iterating operation.
If, as mentioned, M is the binary matrix representing the hypertext network structure,
vj being one of M's column vectors representing node j's outgoing connections,
W is the continuous matrix representing the browser's assessment of association among the network's nodes
ag is one of W's row vectors, representing the incoming connections for node g,
and node g represents the browser's goal in the network
then
initialise M W
[arrowdown] [arrowdown] [arrowdown]
j (position) => vj . ag => n | i ~ Max(n) -> i=g -> end
j = i
In this model, the browser's position is initialised to the position j, j being a network node. In practice, the initialisation could take on the form of searchable indexes or introduction pages that enable users to choose a favourable position from which the browsing can start. From that point on, users navigate from page to page, selecting and rejecting specific links, in order to position themselves as close to the desired information as the network structure will permit. Matrix M expresses network structure. The selection and rejection of hyperlinks within a certain page is based upon the browser's general knowledge of the possible semantic `environment' of the information he or she is trying to retrieve, as expressed by the matrix W. Within a hill-climbing strategy the links from a certain position j in the network should be evaluated according to how close any of these links will take the browser towards his intended position, i.e. their presumed distance to the browser's goal. This evaluation takes place by calculating vector n as the outer product of the binary column vector vj (representing the hyperlinks from hypertext page j) and ag , the continuous row vector of the user's association matrix W (representing the possible incoming connections to goal-node g). Vector n's values indicate how instrumental a certain link will be to move nearer to the goal-position. The maximal value within this vector will be the most optimal hyperlink to choose, if the browser adheres to a hill-climbing strategy. After having selected the most optimal hyperlink, the user will move on to a new position, with a new offering of information and connections.
The following characteristics of the goal-directed browsing process can be derived from this model.
First, the browser seems to be completely dependent upon hypertext network structure. Although browsers can evaluate the alternative links in pages, and are free to pursue alternative paths through the network, their behaviour is entirely confined by the network's structure [Van Dyke Parunak, 1991].
Secondly, the browser's behaviour is determined by the local structure of the hypertext page he is presently retrieving. At each consequent page, he is charged with evaluating the local alternatives and selecting the locally most appropriate connection. Browsers can thus easily end up in local maxima, which is a general problem associated with blind hill-climbing strategies.
Thirdly, the evaluation of hyperlinks with a hypertext page will not likely be computed as the outer product of two vectors. The comparison of present connections with the browser's associative intuitions will be performed in a serial manner. The amount of connections and information within a page will determine the cognitive load placed on the browser.
3.1.4) Linear retrieval: cognitive overhead and information content.
The browser's decision to select a certain hyperlink and reject others (cognitive overhead [Conklin,1987]) can be studied without referral to specific network structure and the browser's associative intuitions. The speed and ease with which certain systems process information, especially serial ones, is determined by the amount of information that has to be processed in order to come to a decision. This effect has been experimentally demonstrated by measuring psychological reaction time as a function of the number of items to be scanned. The amount of information contained within messages or stimuli can be quantitatively expressed by Shannon's measure of information/entropy [Shannon, 1948][Pierce, 1980]and hence the cognitive load on hypertext browsers can be quantified.
According to Shannon, `information' is that which enables a certain system to take decisions when being confronted with several alternatives. Entropy is the negation of information: it expresses the difficulty involved in coming to an appropriate decision. If all alternatives are equivalent or equiprobable, making a decision will be most difficult and entropy will be maximal. Information on the other hand will be minimal. If, however, only one single state is valid, and all other alternatives are impossible, a decision is most easy. In the latter case, entropy is minimal, and information to the system is maximal. Entropy and information can therefore be considered equivalent, but opposite measures.
For a certain situation in which a system is capable of making a transition from its present state S to n number of future states, each associated with a transition probability Pi, entropy H is defined as:
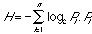 (eq. 1)
(eq. 1)
This equation can easily be applied to the situation in which a hypertext browser is positioned in a certain hypertext page (the system's present state) and is confronted with a number of possible hyperlinks to other pages(future states). The difficulty of the browser's decision concerning the selection of one specific hyperlink and the rejection of all others, can be expressed by Shannon's entropy or information measure, and is in that respect related to the number of alternatives, and the distribution pattern of their associated probabilities.
Consider, for example, a hypertext page on information theory that refers to 6 other pages on the subject. If all of these connections are equiprobable, or equally worthwhile to pursue, then the browser's decision will be maximally difficult, or maximally `uninformed'. When on the other hand 3 connections are positioned on top of the hypertext page and marked with flashing colours, the 3 remaining hidden at the bottom of the page (they are not considered to be equally important), the browser's decision will be much easier. The browser will nevertheless have to choose among three equally well marked links. For a hypertext page with one link on top, marked with a 42 point font, and 5 others at the end of the 10 page hyper-document, the browser's decision will be maximally easy: in practically all cases only one connection will be chosen. This page thus offers minimum entropy and the browser's decision will be maximally informed.
Shannon's measure of information is, when applied to hypertext pages, thus a reverse measure of the energy the browser will have to expend to make a decision regarding the connections to pursue and to reject: an indication of what we will refer to as `decision-energy'.
In fact, `decision-energy' as defined by the amount of entropy within the distribution of hyperlinks in a hypertext document, is in some sense related to the previously discussed fan-effect in human long term memory. The number of semantic components subsumed in items that are stored in human memory, does influence the speed and ease with which they can be retrieved by conscious searches. The number of items, subsumed in hypertext pages, likewise influences the browser's ease to reach an adequate decision.
3.2) Collective browsing and spreading activation.
3.2.1) Collective browsing
Hypertext networks can be stand-alone, isolated systems, designed to be used by individual users, but this need not necessarily be the case. The World Wide Web demonstrates how hypertext systems can escape geographical limitations and serve millions of simultaneously operating users [Berners-Lee et al, 1992] on a global scale.
The factors that determine an individual user's browsing behaviour, network structure and the users' natural associative knowledge, will be very difficult to examine in collectively browsed hypertext networks of this size and nature. First, the WWW's content and structure is known to be highly volatile. The rate of expansion of the number of WWW servers has been enormous during the past few years, and is expected to continue to do so. Even small and relatively isolated parts of the network change rapidly. Links shift, pages move from one server to another, the content of pages changes, etc. Even page coding has changed; the Hyper Text Mark Up language in which WWW pages are coded has regularly been extended and adjusted on behalf of popular demand and technical changes in browser interfaces.
Then, secondly and most importantly, the motives and intentions of individual users can only be guessed at. Network content is practically unlimited, and users can browse for any kind of reason, to retrieve any kind of information. In addition, the use of so-called URL's (Universal Resource Locators) enables users to be directly referred to specific pages by other users, articles, search engines, etc.
We propose to model retrieval of information from collectively used and designed networks such as the WWW in terms of total activation levels as a general measure for the sum of all individual network activity, rather than referring to individual strategies. The assumption would then be that since individual activity can not be accurately described and measured, one could for all practical purposes regard network activity as a distributed, fuzzy flow of activity. From that perspective it is not so much specific, serial activation of network nodes and connections that counts, but overall network flow and connectivity.
3.2.2) Network Flow
Network activity is highly distributed. Most browsers follow an average of 5 paths through as much as 7 different servers per network session [Catledge & Pitkow,1995]. If one assumes each server to contain a total of 15 hyperlinks over all documents stored on that server (an estimate that is probably well under the actual number), then 157 or 170,859,375 documents could be reached in a path through only 7 servers.
But, although general levels of network activity might be distributed and diffuse, this does not necessarily imply it is spread evenly over the entire content of the network. Some servers are immensely more popular than others, even to the extent that they become overtaxed and cease to function. What causes activity to accumulate in certain parts of the network?
Apart from general user preferences, overall network connectivity will be an important factor determining the properties of collective information retrieval. Some parts of the network are often referred to, and receive many incoming connections. Other parts might not be well integrated into the WWW's tissue, and might perhaps receive no incoming connections at all. Since traversing connections between different documents, i.e. browsing, is most likely the user's preferred way to retrieve information, and users have been shown to be referred to an average of 7 servers per session, the extent to which a certain server or page is visited will be strongly determined by the amount to which it is connected to the rest of the network. In other words, network activity will accumulate at well-connected hypertext documents because user activity is highly distributed and users tend to make extensive use of hyperlinks.
The properties of collective browsing in shared hypertext networks resemble those of information retrieval in human memory. This is in line with a number of recent articles that discuss the brain-like properties of the World Wide Web. One could model the functioning and properties of the WWW as if it were a global brain capable of independent functioning and reasoning [Heylighen&Bollen, 1995][Mayer-Kress, 1995] The combined activity of human browsers could be seen as the flow of activation through this global brain, its emerging mechanism of retrieval.
As far as the connectivity hypotheses for human long term memory is concerned, one could imagine the same effects to take place in the Word Wide Web. Connectivity theory predicts that the more components a memory item has, the better are its chances of being well integrated in long term memory, and the easier it will be to retrieve. This holds for hypertext pages as well. Pages that denote complex concepts will generally have to refer to more other pages (sub-concepts to represent the page's meaning) than pages that denote simple concepts. The amount to which a certain hypertext page is integrated into the network, i.e. how many pages it refers to and how many pages it receives connection from, determines how easily users can contact and retrieve that specific page. In terms of overall network activity, pages that represent complex concepts will thus receive more general activation; i.e. they will be more frequently retrieved, because they are more easy to retrieve.
3.2.3. Quantitative analysis of network connectivity.
In the absence of detailed information regarding the precise number of out-going connections per page, and the exact pages they refer to, the degree of network `connectedness' could be inferred from its statistical properties as a random network.
[Rapoport, 1967] discusses how exchanges in random social networks can be modelled without refering to the exact pattern of connections within the network. Consider a random network of nodes, N denoting the total number of nodes. Each node in the network connects ad random to a certain number a of other nodes. Presuming no node can contact itself, and a certain node can only be contacted once, how many nodes can be contacted by traversing the random connections in the network, starting from a set of randomly chosen nodes?
Rapoport proposes the following equation to determine each consequent fraction of contacted network nodes under the previously discussed conditions:
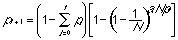
Pt+1 is a fraction of the
total number of nodes that have been contacted from the previous fraction
pt. The first factor of equation expresses the probability
that a certain node has not already been contacted. The second factor expresses
the probability that a connection between the previous node and the contacted
node does exist. Note that
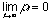 ,
but the total of contacted nodes
,
but the total of contacted nodes
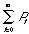 need not necessarily equal 1. For sufficiently large networks, and a
sufficiently low number of contacts per node, parts of the network might never
be contacted. The evolution of Pt will be
such that initially the number of contacted nodes increases as each contacted
node on itself can contact other nodes it connects to. However, after the
initial expansion of the number of newly contacted nodes,
Pt will start to decrease because the random
connections from each node increasingly terminate on nodes that have already
been contacted. In other words, chances of any node randomly connecting to
another not yet contacted node will diminish. Even to the extent that the
process might terminate before the entire network has been contacted, leaving
the total fraction of contacted nodes at values much lower than 1.
need not necessarily equal 1. For sufficiently large networks, and a
sufficiently low number of contacts per node, parts of the network might never
be contacted. The evolution of Pt will be
such that initially the number of contacted nodes increases as each contacted
node on itself can contact other nodes it connects to. However, after the
initial expansion of the number of newly contacted nodes,
Pt will start to decrease because the random
connections from each node increasingly terminate on nodes that have already
been contacted. In other words, chances of any node randomly connecting to
another not yet contacted node will diminish. Even to the extent that the
process might terminate before the entire network has been contacted, leaving
the total fraction of contacted nodes at values much lower than 1.
Under the presumption of constant network size, the evolution of
Pt depends completely on the size of a, the
number of contacts per node. The number of iterations, t, that it takes
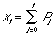 to
reach a certain threshold, could be used as a general measure of network
connectedness. This measure would be dependent only upon the network's average
amount of branches per node, a.
to
reach a certain threshold, could be used as a general measure of network
connectedness. This measure would be dependent only upon the network's average
amount of branches per node, a.
Consider for example a certain node A from which the iterative `branching'
of contacted nodes in the random network starts at
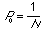 .
xt denotes the chances of a certain node B
belonging to the set of contacted nodes at time t, i.e. the probability
that a random node B can be or will be reached from a random node A, given a
specific number of iterations. The number of iterations necessary to indirectly
contact node B starting from node A, with a certain minimum probability
(threshold) can as such be used as a measure of network connectedness.
.
xt denotes the chances of a certain node B
belonging to the set of contacted nodes at time t, i.e. the probability
that a random node B can be or will be reached from a random node A, given a
specific number of iterations. The number of iterations necessary to indirectly
contact node B starting from node A, with a certain minimum probability
(threshold) can as such be used as a measure of network connectedness.
For example, for a certain network, containing 1000 nodes that each branch to 4 other nodes in the network, the evolution of the respective xt values would be as in table 1.
t
0
1
2
3
4
5
6
7
8
Pt
0,001
0.004
0.02
0.08
0.27
0.67
0.93
0.97
0.98
Table 1: Evolution of the number of contacted network nodes as a fraction of the total number of nodes according to eq. 1.
The statistical `connectedness' of random networks with different number of branches can be compared according to when the probability xt for a network reaches a certain threshold.(assuming networks have equal number of nodes N and an equal number of starting nodes). If, for example, we would recalculate the probability values for the same network as in table 1 for a different number of branches (a=6), we could compare these two network according to when the respective xt's reach a certain threshold (e.g.>0.95).
t
0
1
2
3
4
5
6
7
8
a=4
0,002
0.004
0.02
0.8
0.27
0.67
0.93
0.97
0.98
a=6
0.002
0.04
0.22
0.74
0.98
...
Table 2: Evolution of "contact-probability" for two networks with different number of branches per node.
As the values in table 2 demonstrate, the 6-branches network's calculated contact-probability reaches the proposed threshold at the 4th iteration of the contacting process, while the 4-branches network requires 7 iterations. This indicates that due to a larger number of branches, the second network has higher overall connectivity.
If we look at the evolution of the number of necessary iterations necessary to make the contact probability achieve a certain threshold in relation to the number of branches per node, we could calculate the following values for a network containing a constant number of 450 nodes (threshold at 0.95, values linearly extrapolated in between integer number of iterations).(table 3)
a
4
5
6
7
8
9
10
11
12
l
6.8
5.9
5.4
4.9
4.8
4.7
4.6
4.2
4
Table 3: Number of iterations to make fraction of contacted node reach threshold as a function of the number of branches per node in the network.
The values in table 3 show that the different number of iterations at which the required threshold probabilities are obtained, can be used to compare the connectedness of random networks of the same size, but of a different number of branches per node.
4.1) Two opposing factors.
The probability that a certain node can be reached from a certain other node in a random network, could be used as a measure of the network's connectedness. Cognitive overhead has been defined as the amount of statistical entropy within the distribution of transition probabilities among the hyperlinks within a hypertext page.
Both measures can be derived from one and the same variable: the number of branches or hyperlinks per page, and both have an opposite effect on the related efficiency with which hypertext networks can be browsed.
From the level of collective browsing and the diffuse spreading of activation, network connectivity should be as high as possible. This implies a high number of connections among the different nodes in the network and thus a high number of hyperlinks per page.
Cognitive overhead on the other hand, defined as the amount of information-theoretic entropy among the connections within hypertext pages in the network, determines the cognitive demands on the individual browser and will hamper his or her ability to make adequate decisions. Pages that contain many equiprobable hyperlinks will demand more `decision-energy', than pages that contain fewer and differently marked hyperlinks.
The demands placed on individual browsers influence the efficiency of retrieval, just as well as overall network connectivity. Browsers should be able to make adequate decisions during their goal-oriented path through hypertext networks. Even with a moderate amount of bifurcations per page and moderate length of browsing path, users can easily end up in unintended parts of the network by making a single mistake. In general, one could state that network retrieval efficiency decreases with increasing cognitive overhead.
Clearly, the precise balance of both cognitive overhead and network connectivity will finally determine the network's efficiency.
4.2) Balancing decision-ease and network connectivity.
4.2.1) Cognitive overhead and decision time.
Since the precise distribution of transition probabilities among the hyperlinks within our hypothetical network are unknown, we will have to assume a worst-case scenario in which all hyperlinks are equiprobable. The probability will be evenly distributed over all hyperlinks and entropy will be maximal for any given number of links, a. Each Pi will equal 1/a, which will reduce equation 1 to the following form:
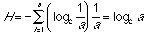 (eq. 3)
(eq. 3)
Table 2 shows the evolution of cognitive overhead as defined by equation 3 with an increasing number of hyperlinks per page.
i
Table 4: Cognitive overhead as a function of the number of hyperlinks.
2
3
4
5
6
7
8
9
10
11
H
1
1.59
2
2.32
2.58
2.8
3
3.17
3.32
3.45
As said, cognitive overhead represents the difficulty with which browsers will be able to evaluate a certain number of alternative hyperlinks: the amount of energy or time they will have to invest in selecting the most adequate hyperlink. As cognitive overhead increases according to the increased amount of alternative hyperlinks in a page, so will the amount of time t a browser will need to evaluate these alternatives and choose one: t can thus be considered a function of H
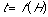 (eq. 4)
(eq. 4)
Assuming a linear relation, we can express the expected time a browser would need to evaluate the alternative hyperlinks in a page as follows:
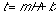 (eq.
5)
(eq.
5)
in which m would represent the extent to which changes in cognitive overhead would relate to decision-time and b a constant bias. (choosing among only one hypertext link will still require a minimum amount of time).
Substituting H for eq. 3, decision-time per individual page can be formulated as:
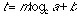 (eq. 5)
(eq. 5)
4.2.2) Network connectivity and browsing time.
Network connectivity on the other hand was defined by the probability of contacting a certain node B (or node B belonging to the set of indirectly contacted nodes) starting from a certain node A in a randomly structured hypertext network.(eq. 2) The number of required iterations, l, in order to make this probability reach a certain threshold was considered to be an indication of the network's degree of connectedness. Determining factors for l's value were the size of the network involved (N=total number of nodes) and the number of branches, a, from each node in the network. Under the assumption of constant network size, the number of required iterations can be expressed as a simple function of the number of branches per node/page in the network.
The number of required iterations l as a measure of network connectedness can be related to the average path length, p, between nodes in the network, or in other words the number of links a browser will have to traverse in order to get from a random node in the network to the desired position.
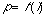 (eq. 6)
(eq. 6)
We can therefore derive the total amount of time, ttot involved in reaching a certain node from any other for a network of a given number of branches.
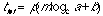 ,(eq.
7)
,(eq.
7)
which will be the product of the decision-time required by browsers at each individual hypertext page in the path and the expected number of decision in the path, i.e. its length p.
ttot will be an inverse expression of the efficiency of the network in question. As ttot increases, browsers will experience greater difficulty browsing the network (increased cognitive overhead or number of traversals). On the other hand, as ttot decreases, network efficiency will increase: browsers will more readily retrieve specific nodes from the network.
Assuming network content to be constant, ttot is completely dependent upon, a, the average number of branches from the nodes in the network, to which the overall connectedness of the network in question and the the amount of cognitive overhead to which the browser is subjected, are related.
The question of interest is whether an optimal configuration of both path length and decision-time can be derived from the minima and maxima of eq. 7. At present, this is not possible due to the undetermined parameters and nature of the relation between the network connectivity measure and average path length as specified in eq. 6. A number of hypothesis and predictions concerning hypertext network efficiency can nevertheless be inferred.
It was the intention of this paper to demonstrate that the efficiency of hypertext networks can be inferred from a very elementary parameter concerning the overall structure of the network in question. Much like the complexity/connectivity problem in retrieval from human memory, the efficiency of hypertext networks seems to be related to the different mechanisms of retrieval that operate upon the network. The first assumption is that individual browsers apply certain optimising heuristics to "tune-in" on the desired information, thereby serially scanning through the content and links of individual hypertext pages. This assumption allowed us to use Shannons measure of information to desribe the speed with which human browser are able to make a selection among the alternative hyperlinks in page.
The second assumption, namely that the characteristics of the WWW as a collectively browsed, global hypertext could be described from the viewpoint of a retrieval mechanism using parallel spreading activation (i.e. the community of its browsers), enabled us to model the general connectivity of large hypertext networks without referring to their specific structure and content.
Although both retrieval mechanism are very different in nature, the efficiency with which they can operate on a certain hypertext network can be inferred from one very basic parameter: the (average) number of hyperlinks within each page of the network (eq. 7). The number of hyperlinks in each hypertext page of the network, enhances the connectivity of the network by shortening possible paths between two nodes in the network, but on the other hand decreases the speed and ease with which human browsers can evaluate the contents and hyperlinks within the pages of the network. The precise quantitative relation between both factors and hypertext network efficiency has not been made clear. However, a certain number of hypotheses can be put forward.
a) the relation between cognitive load and network connectivity is multiplicative. This suggests that networks with either low cognitive load (few links) and low connectivity, or high cognitive load and high connectivity will not be efficient. Both parameters will have to be equally beneficial. Individual hypertext pages need to be constructed so as to allow users to make quick and accurate choices, and the hypertext networks in which they are embedded will have to be designed to minimise distance in terms of path length between nodes of the network.
b) the proposed analysis can be applied to different networks as well as to different parts of the same network. As mentioned, the content and structure of a hypertext network as large as the WWW can be very heterogeneous in terms of complexity and connectivity. Certain parts of the network can be highly interconnected (high a: high connectivity, high overhead) while other have only few connections (low connectivity, low overhead). High complexity parts of the network can be identified because activation tends to accumulate and the speed of browsing decreases. Low complexity parts of the network can be identified just as well because of fast browsing, but a low tendency of accumulation. Additionally, the amount and intensity of clusters in the network can be empirically detected by deriving a values from measurements of the characteristics of browsing activity. The evolution of these a values can be measured and compared to the mathematically predicted values under the assumption of constant network `complexity'.
c) our analysis of the cognitive effort and time involved in evaluating individual hypertext pages, assumed equiprobability among the alternative hyperlinks within the pages and as a consequence a detrimental influence of the number of these links on browser linking speed and efficiency. However, in practice links are seldom entirely equiprobable. First, independently of hypertext network structure the typecasting and specific design of each page in the network makes certain links more probable to be selected than others and will alleviate some of the load on browsers. The hypertext designer's insight and intuition will thereby implicitly control browsing behaviour. Whether this effect will enhance retrieval efficiency or not will depend on another more important factor. In accordance with the proposed model of heuristic browsing, hyperlinks can never be entirely equiprobable, because the essence of the model of heuristic browsing is that browsers apply their common sense of association and relation to the links they are being offered. The question then being whether the links within the hypertext page are compatible with these associative assessments or not. If they are, browsers have better opportunities to retrieve the information they desire, while at the same the network is allowed to contain more hyperlinks per page for a lower level of cognitive overhead or decision-effort as defined in equation 5. Cognitive load and network connectivity are multiplicative factors and a relative improval of overall network connectivity can thereby indirectly be achieved by making the selection probabilities of links more compatible with pre-existing browser knowledge.
d) the mentioned analogy between retrieval by spreading activation in human memory and the characteristics of collective browsing through the world wide web introduces the notion that pages in the network are being visited and browsed by a wide variety of individuals. This raises the problem of whether or not the specific and fixed design of hypertext pages and the structure of the hypertext network in which they are embedded, conforms to characteristics shared by all of its browsers and visitors. A number of techniques in the field of Flexible Hypertext have been proposed that can alter the appearance and structure of WWW networks [Bollen & Heylighen, 1995], so as to fit an as large majority of browsers as possible[Kaplan,1993][Mathe, 1994]. In accordance with the proposed relation between network connectivity and user cognitive load, this system uses an ordering of suggested links from a hypertext page to enhance browser's evaluation speed (decreasing equiprobability) [Tomek, 1994] and at the same time applies a mechanism of transitive and symmetric closure to shorten distances in the network structure. To ensure maximum evaluation speed, the network uses measurements of local user paths to adapt the hypertext's network structure to its browsers' common associations.
An analysis in terms of cognitive load on browsers and overall connectivity of the networks they produce, might perhaps enable researchers to more effectively compare the mentioned systems for flexible hypertext and adaptive user interfaces.
* Berbers-Lee, T., Cailleau, R., Groff, J.F. and Pollerman, B (1992), World Wide Web: The Information Universe, Electronic Networking: Research, Applications and Policy.xxx
* Bollen, J. & Heylighen F. (1996), Algorithms for the self-Organization of distributed, multi-user networks. Possible applications to the future WWW., in Trappl, R. (ed.), Proceedings of the 13th European Meeting on Cybernetics and Systems Research, Austrian Society for Cybernetic Studies, Vienna, p. 911-917.
* Bush, V. (1945), As We May Think. Atlantic Monthly, 176/1, July, p. 101-108
* Canter, D., Rivers, R. and Storrs, G. (1985), Characterising User Navigation through Complex Data Structures. Behaviour and Information Technology, 4(2), p. 93-102.
* Catledge, Lara D & Pitkow, James E. (1995), Characterizing Browsing Strategies in the World Wide Web. Computer Networks and ISDN Systems, 27, p.1065-1073
* Conklin, J (1987), Hypertext: An Introduction and Survey, IEEE Computer, September.
* Cove, J.F. & Walsh, B.C."On-Line Text Retrieval via Browsing", Information Processing and Management, Vol. 24, No. 1, 1988., p. 31-37
* Genter, D. (1981), Verb Semantic Structures in Memory for Sentences: Evidence for Componential Representation. Cognitive Psychology, 13, p.56-83
* Heylighen, F. & Bollen, J. (1995), The World Wide Web as a Super-Brain: From Metaphor to Model, in Trappl, R. (ed.), Proceedings of the 13th European Meeting on Cybernetics and Systems Research, Austrian Society for Cybernetic Studies, Vienna, p. 917-923.
* Hinton, Geoffrey & James Anderson (1981) (eds). Parallel Models of Associative Memory, Hillsdale, N.J.
* Jonassen, D.H. (1990), Semantic Network Elicitation: tools for structuring Hypertext. In R. McAleese and C. Green (eds.) Hypertext: State of the Art. Oxford, Intellect.
* Kaplan C., Fenwick J. & Chen J., (1993), Adaptive hypertext navigation based on user goals and context. User models and user adapted interaction, 3(2).
* Klimesch (1994), The Structure of Long term Memory: A Connectivity Model of Semantic Processing, Lawrence Elrbaum and Associates, Hillsdale.
* Kroll, N.E.A. & Klimesch, W. (1992) Semantic Memory: Complexity or Connectivity?, Memory and Cognition, 20, 2, p.192-210.
* Mathe, N. & Chen, J. (1994); A User-Centered Approach to Adaptive Hypertext based on an Information Relevance Model; Proceedings of the 4th Int. Conference on User Modeling, Hyannis, MA, August 15-19. pp. 107-114.
* Mc. Clelland, J. & Rumelhart, D. E. (1986) Parallel Distributed Processing. Volume 1: Foundations, Bradford Books, MIT Press.
* Mayer-Kress, G. (1995), Global Brains and Communication in a Complex Adaptive World, in Trappl, R. (ed.), Proceedings of the 13th European Meeting on Cybernetics and Systems Research, Austrian Society for Cybernetic Studies, Vienna, p.923-928
* Pierce, J.R. (1980), An introduction to Information Theory: Symbols, Signals and Noise. New York, Dover Publications Inc.
* Rapaport, Anatol (1963), Mathematical Models of Social Interaction, in R. Luce, R. Bush & E. Galanter (eds) Handbook of Mathematical Psychology, New York, John Wiley & Sons, 2, 513-515
* Shannon (1948), A Mathematical Theory of Communication. Bell System Tech. J., 27, p. 379-423
* Snowberry, K., Parkinson, S. and Sisson, N. (1985) Effects of Help Fields on Navigating through Hierarchical Menu Structures. International Journal of Man-Machine Studies, 22, p. 479-491
* Schildt, Herbert (1987) C - The complete reference (AI-based problem solving), Osborne- Mc.Graw Hill, London, p. 645
* Tomek I., Maurer, H. & Nassar M. (1993), Optimal presentation of links in large hypermedia systems. In Proceedings of ED-MEDIA '93 - World Conference on Educational Multimedia and Hypermedia. AACE, p. 511-518
* Van Dyke Parunak, H. (1991), Ordering the information Graph, in, Berk, E & Devlin J. (eds.) Hypertext and Hypermedia Handbook, p. 299-325.