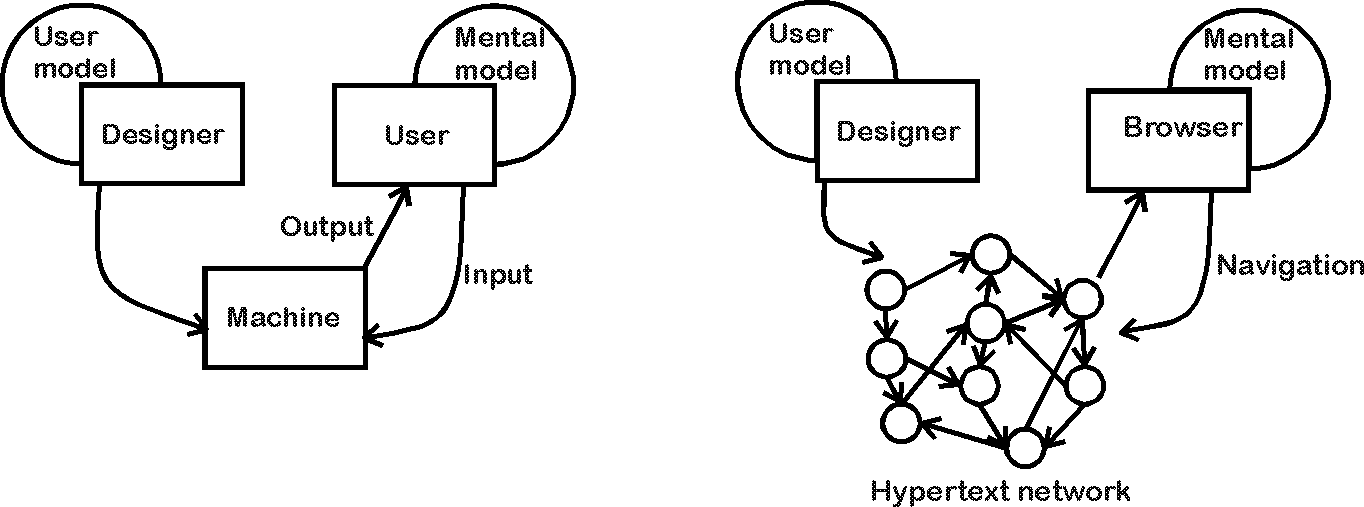
fig. 1. The analyses of the hypertext-browser systemâs interactions in terms of user and mental model.
A connectionist system to restructure hypertext networks into valid user models.
Johan Bollen & Francis Heylighen
Vrije Universiteit Brussel
Leo Apostel Center
Krijgskundestraat 33
1160 Brussel
Abstract:
The efficiency of browsing hypertext networks is determined by the interaction between two distinct models: the user model that the designer uses to structure the network and the browserâs mental model that he/she uses to browse the network. The degree of similarity between both models will determine how easy or how difficult browsers can retrieve information from the network. Since browsersâ mental models are difficult to control and shape, the present paper proposes a connectionist system that automatically restructures hypertext networks according to the browserâs mental models. The system uses a set of three learning rules that change connection strengths in the network based on implicit measures of the browsersâ collective mental models. The system has been shown to make hypertext networks reliably and validly mimic the browserâs collective mental models in two in situ experiments and a simulation using a mathematical model of browser navigation.
The Internet and its associated WWW (World Wide Web) hypertext protocol (2) have been experiencing an exponential growth during the past few years. Not only the number of users and Internet servers but also the amount of electronic information stored has been growing at an astounding pace.
In spite of its popularity among publishers and users, the WWW doesnât seem to be entirely living up to the expectations. With a growing number of pages and an increasing number of links, users are experiencing more and more difficulties to retrieve the information they require (9)(23). Many researchers have proposed specific instruments to alleviate the problems of navigating hypertext for information retrieval but few of these systems have actually been experimentally tested for their efficiency in improving navigation.
We believe that an analysis of the cognitive mechanisms involved in browsing can shed some light on how the efficiency of retrieval from hypertext networks can be improved by shaping the network to represent the browsersâ shared mental maps. Following from this analysis, we will propose a system for the dynamic updating of hypertext links according to browsersâ overlapping mental models. This system has been tested in situ as well as in controlled experiments.
People that interact with machines have certain preformed expectations about its functioning and operation. These expectations (or predictions) are generated by the userâs model of what the machine is and what it does. This model is commonly referred to as the userâs mental model (1). Unfortunately, mental models need not necessarily be good models of how machines really function and how they will behave. Most machines are designed independently from their potential users. Their specific implementation will be strongly influenced by the designerâs set of expectations about the typical user. This set of expectations is often referred to as the designerâs user model that will determine a machineâs overt behavior towards the user. The machineâs user model can be quite different from the userâs mental model in which case the interaction between user and machine can become highly inefficient and erroneous. Generally, the congruency between both user model and mental model are considered vital for the efficiency with which humans can interact with machines (25)(32).
The hypertext-browser system can be functionally analyzed in the same sense as shown in fig. 1. Functionally the process in which human browser navigate hypertext networks can be modeled as the interaction between:
fig. 1. The analyses of the hypertext-browser systemâs interactions in terms of user and mental model.
This analysis suggests that there are two distinct ways to improve the efficiency of retrieval from hypertext systems. First, the browserâs mental model might be made more similar to the systemâs user model. Second, the systemâs user model could be made more similar to the browserâs mental model.
Some systems have concentrated on adapting the browserâs mental model to the systemâs characteristics by explicitly informing browsers about the underlying network structure (34) by means of visualization tools, graphical maps, guided tours, etc. (29). A number of learning effects might be induced to help the browser cope with specific hypertext systems (8)(16). This approach, however, has a number of serious limitations. First, people in general have preformed ideas about the associations of concepts in general (31)(20) and these will often interfere with new information about the structure or content of a certain hypertext network. Second, mental models are not directly accessible. They can only be measured indirectly through related variables such as introspection, tests of acquired knowledge, etc·(17)(24) They can also not be controlled directly. The mental model of browsers can thus not simply be changed by direct intervention.
The most straightforward approach to improving the efficiency of retrieval from hypertext systems thus seems to be the adjustment of the systemâs user model to the browserâs mental model. A large part of the literature on adaptive hypertext and hypermedia has been concerned with this problem (4). Many authors have described ways to measure the browserâs preferences, interests or abilities, and changing the behavior of the hypertext system accordingly (18). A typical system will for example query users for their educational level and change its responses in accordance with a consequent categorization of the individual user as an expert or layperson. Other systems implicitly infer user characteristics from e.g. the personal interests browsers express in reading certain pages (30), to make the system preferentially present pages that correspond to these interests. Some systems even learn to categorize users and dynamically adapt the systemâs output. This approach has yielded some very interesting systems and results (22).
The notion of user modeling for hypertext and hypermedia has mostly been interpreted as the construction of systems for user categorization external to the hypertext network and to apply these to change the hypertext systemâs overt behavior. However, as has been argued, hypertext networks in themselves can be interpreted as user models in their own right. When designers of hypertext networks link together pages and items, they are making their subjective user models explicit. The structure of the resulting network is thus an explicit representation of the designerâs user model and it could be changed to be more similar to the browserâs mental model.
To do this, we need reliable measures of the browserâs mental model. Most techniques in the psychological literature on the measurement of meaning and word association norms rely on procedures in which large groups of human subjects explicitly name or indicate the associations to a certain word (21). This methodology could be applied to adapt certain hypertext systems, but it is generally too static and too obtrusive to be applied to the WWW.
Models of the browsersâ shared mental model could, however, be derived from implicit measures of general browsing behavior. The fact that a browser uses a connection between 2 hypertext items could for example be used as an indication that the two hypertext items are associatively related in the browserâs mental model. Consequently the more frequently a certain connection between 2 hypertext items is being traversed by browsers in general, the stronger these two items are related in the browserâs mental model. The overlapping choices of a sufficiently large group of browsers to use certain hyperlinks and not others can thus be used as an implicit measurement of these browsersâ shared mental maps. These measurements can consequently be used to shape the structure of hypertext networks.
We have implemented a connectionist (26) scheme for the dynamic restructuring of hypertext that combines the above outlined concepts of mental model - user model similarity and the implicit measurement of browsersâ shared mental model. The system makes hypertext systems restructure themselves while they are being browsed, with little or no intervention from the human designer. We think this is the best way to ensure an as large as possible overlap between the browsersâ mental model and the networkâs user model.
The proposed system closes the feedback loop between browser and network by implementing the following (fig. 2):
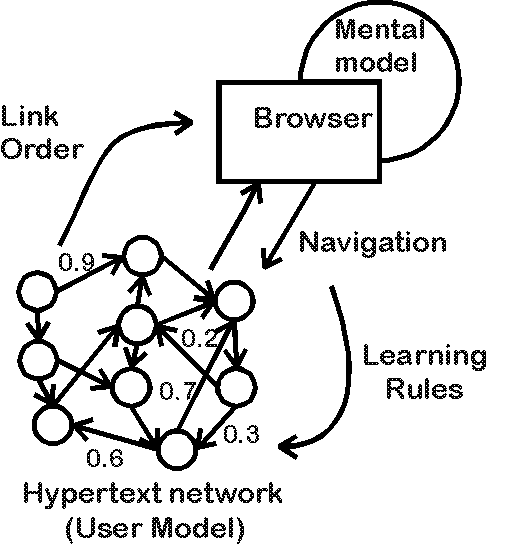 changes in network structure are fed back to the user by ordered presentation of links according to decreasing connection weight
changes in network structure are fed back to the user by ordered presentation of links according to decreasing connection weight
fig.2: The adaptive hypertext system closes the feedback loop between network development and browser.
Hyperlinks are directional and Boolean; i.e. they point from one page to another and are either present or not present. They can not be modulated in terms of link relevance or quality. A certain form of link modulation can however be very useful. Human browsers for example need to assign strength of relation to the links from a given hypertext pages to be able to browse the network. Otherwise, all connections would be considered equally relevant and the user could not selectively navigate towards any specific position in the network. In order to enable the automatic restructuring of hypertext networks as intended by our system, we decided to enable the system to assign connection weights to the hyperlinks in the hypertext network. This would allow the system to modulate existing connections without their actual removal/creation within the hypertext pages and use the weights as evaluations of relevance.
The following set of 3 learning rules was implemented. They locally change connection strengths according to whether browsers select a specific connection or not (fig. 3).
These learning rules operate strictly locally, i.e. during browsing, and in parallel.
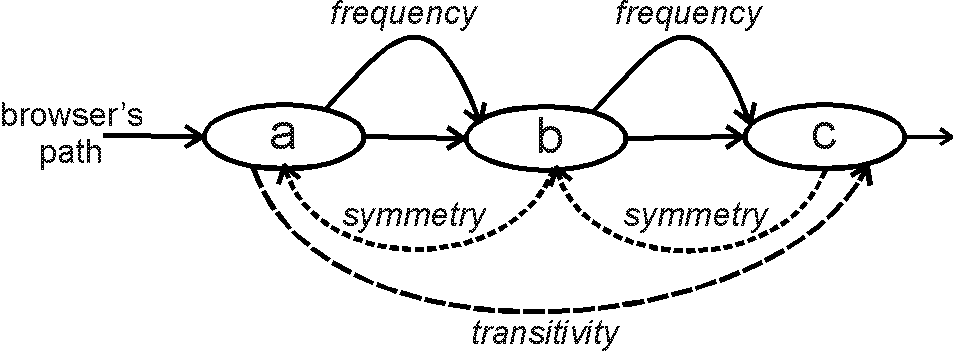
fig. 3.: Schematic overview of learning rules function.
The experimental system was set up to feed back changes in network structure to its browsers by link ordering according to descending connection strength. Any page in the network would contain an ordered list of links in which the strongest connections would appear on top. The principle of ordered presentation of choice items has a number of advantages. At least one thorough analysis of collective browsing behavior has found a strong relation between the ordered position of hypertext links and their probability of being selected (13). If we can assume the system functions as intended, the most appropriate connections from a given page have the highest connection strength. They should thus appear on top of the link list to have the highest probability of being selected. Efficient link ordering has also been shown to improve selection times and reduce cognitive overhead (3)(28)(33). In real hypertext systems connection strength can be communicated in many other ways such as link coloring, font size, etc, but due to the experimental nature of the system outlined in this paper we chose to use the most proven and simple technique.
The previously outlined system for adaptive hypertext restructuring has been tested in two in situ experiments to study the effects of collective browsing in an adaptive hypertext system on the WWW. The adaptive hypertext networks consisted of the 150 most frequent English nouns and were made available to a wide audience of voluntary participants that could access and train the networks from the WWW. This experiment yielded a large base of technical data, but its setup lacked reliable measures of the browsersâ mental models. In order to test the networkâs assumed capability to change its structure according to the browsersâ mental models, we devised a series of simulations using a programmed, artificial browser.
The 150 most frequent English nouns were derived from the LOB-corpus (15) and used as nodes for the experimental network. The number 150 seemed to be a reasonably large amount of nodes to provide browsers a rich and large enough network to browse and to train, while the resulting data would still be manageable in later analysis.
The decision to use single nouns as nodes for the networks rather than real hypertext pages was based on the consideration that node content is a strong determining factor that induces an according network structure. To be able to generalize our results, we thus decided to focus on hypertext structure rather than node content and used one-word nodes for the experimental hypertext network even if this reduction might reduce the face validity of our results.
Our use of the 150 most frequent English nouns can be justified by the assumption that frequent nouns have a more distinct and constant meaning among speakers of the language than less frequent ones. Word frequency is also a relatively a-select criterion for the selection of words.
A HyperCard stack was setup for each experiment. It contained the network nodes, their weighted connections to all other nodes in the network and the software that implemented the systemâs learning rules. At the start of each experiment, the Hypercard stack initialized the connections between all words in the network to small random values (<0.1) for a first random ordering of hyperlinks.
Upon first contact the stack assigned each participant a random starting position in the network from which the browsing session could start. The stack would then generate the appropriate hypertext pages from which the participants could browse the network. The generated hypertext pages consisted of:
When the user selected one of the listed hyperlinks, the HyperCard stack was contacted via our WWW server and shifted the browserâs position to the selected node by returning a new hypertext page corresponding to the requested one with a new ordered list of links. At each consequent selection the adaptive system would apply the learning rules to the selected connections.
The hyperlinks in the pages contained so-called packed queries (10), i.e. their URLâs (Universal Resource Locater: a website address) were generated in advance to contain the names of the two, last requested nodes. When users selected a link from the list, the URL itself thus informed the adaptive system of where the browser was coming from so it could execute the transitivity and symmetry learning rules.
The HyperCard stack was set up to apply two learning rules in the first in situ experiment, i.e. Frequency and Transitivity, and to extend these with the Symmetry learning rule for the second experiment. Each learning rule applied a different reward to the connections they reinforced. The rewards were independent from the connectionâs weight.
First, the frequency learning rule was set to apply a reward of 1, so each time a browser traversed the connection between a node a and a node b this connectionâs weight was increased with a value of 1.
Second, the transitivity learning rule was set to apply a reward of 0.5. Each time a browser used a hyperlink between a node a and a node b, and consequently the hyperlink between node b and a node c, the connection between node a and node c was increased with a value of 0.5. The reward for the Transitivity learning rule was set to this level because the rule, contrary to the Frequency learning rule, rewarded connections that hadnât actually been selected by the browser. Although transitive connections are highly plausible in many cases, they can be spurious. For example, if a browser connects cat and milk, and afterwards connects milk with cheese, the transitive connection, i.e. cat and cheese is not necessarily a valid one. The lower value of 0.5 was chosen to reflect the estimated probability of rewarding these spurious links.
Thirdly, the Symmetry learning rule, which was only used in the second experiment, applied a reward of 0.3. So, each time a browser used the connection between a node a and a node b, the connection from b to a was increased with a reward of 0.3. The value of this learning ruleâs rewards reflected our estimation of how relevant symmetric connections would be compared to the transitive ones.
After setting up the adaptive hypertext system we sent requests to participate to all relevant mailing lists and newsgroups. The request included a sketchy overview of what the experiment was like and a URL that pointed to the WWW server on which the experiment was conducted. Participation to the experiment was entirely voluntary and anonymous. We registered no personal information but participants were encouraged to answer a few personal questions after having completed the experiment.
When contacted our server returned a brief explanation of the experimentâs interface and general instructions concerning browsing strategies, etc. No mention was made of the experimentâs goal or implementation. In general we advised people to browse the network as they would browse any other hypertext network (5)(6)(7). Rather than feeling tested and expressing the most personal associations and links, subjects should associatively wander from page to page and choose hypertext links that were most related to their present position in the network. The one-page instructions ended in a hypertext link that pointed to the actual experimental network. Browser could exit the network at any time by selecting "exit".
A total of 12000 requests were received in both experiments. The first hypertext experiment received as many as 4600 requests while the second experiment received at least 6000 requests. Samples from the server logs showed that participants individually selected about 10 links per session. If most people tried the experiment once and did not return, then the 2 experiments attracted an estimated total of 600 participants each. Both experiments lasted about 1month. The experimental hypertext system saved a copy of network structure every 200 requests for later analysis.
Both experiments started from an entirely random structure, but rapidly developed meaningful connections from all nodes. Although browsers were set to start browsing from random positions in the network, the browsing activity seemed to concentrate on a rather limited set of nodes in the network. This effect seemed to be more pronounced in the first experiment. Nevertheless, most nodes in both experiments were reasonably frequently retrieved and browsed to develop a set of relevant connections to the other nodes in the network. An example might demonstrate how links developed in the network. Table 1 shows how connections from the node MIND developed during the first 4250 established user selections in the second experiment. At first the ordered list of links from the node MIND consisted of nothing more than random, meaningless connections as a results of the initial assignment of random connection weights. After 600 selections a number of meaningful connections like Îthoughtâ, Îideaâ and Îresearchâ showed up on top of the list. A number of lower ordered connections such as Îlawâ and Îlightâ however remained, as remnants of the initial random ordering. After about 1200 links, all ordered links seemed to be sufficiently associated with MIND, but the order of links in the list was still being refined. ÎKnowledgeâ and ÎDevelopmentâ for example had shifted upwards and had passed Îresearchâ that had shifted down. After about 2400 connections the list with connections seemed to have stabilized as no new connections appeared. Only the order of the links changed slightly. The list of links from MIND had achieved a more or less stable structure in which each connection had taken a position that best reflected its semantic or associative strength of relation to MIND.
|
MIND |
|||||||||
|
Link Order |
|||||||||
|
1st |
Table |
Thought |
Thought |
Thought |
Thought |
||||
|
2nd |
Order |
Idea |
Idea |
Idea |
Idea |
||||
|
3rd |
Figure |
Research |
Knowledge |
Knowledge |
Knowledge |
||||
|
4th |
Party |
Problem |
Change |
Theory |
View |
||||
|
5th |
Question |
Need |
Development |
Development |
Education |
||||
|
6h |
School |
Light |
Research |
Change |
Theory |
||||
|
7th |
Act |
Development |
View |
Research |
Development |
||||
|
8th |
History |
Change |
Need |
View |
Research |
||||
|
9th |
Fact |
View |
Problem |
Need |
Change |
||||
|
10th |
Wife |
Law |
Theory |
Education |
problem |
||||
|
Links: 0 |
600 |
1200 |
2400 |
4200 |
|||||
Table 1: Development of connections from the network node MIND from initial random state to condition after 4200 selections.
The symmetry learning rule was added in the second experiment to speed up network development by allowing the network to produce a greater variety of links that could be selected upon by the Frequency learning rule. How did this influence network development speed?
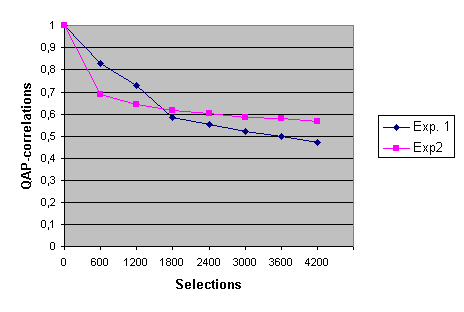 Network development speed can be operationalized as the difference in QAP network correlation (14) between each consequent network structure and the first registered network structure. If the difference in correlation between two consequent stages of network development and the first network is low, less development has taken place during the two consequent measures. If, on the other hand, this difference in correlation is high, the speed of network development has been high during the two measurements. Since the networks start from a random structure the second first network structure is correlated to all consequent networks. Graph 1 shows network development for both experiments. The graph shows that network development in both networks is very fast during the first 1800 connections and then decelerates. Network development in the second experiment is slightly faster than in the first experiment for the first phases of network development, but reaches its asymptote sooner afterwards.
Network development speed can be operationalized as the difference in QAP network correlation (14) between each consequent network structure and the first registered network structure. If the difference in correlation between two consequent stages of network development and the first network is low, less development has taken place during the two consequent measures. If, on the other hand, this difference in correlation is high, the speed of network development has been high during the two measurements. Since the networks start from a random structure the second first network structure is correlated to all consequent networks. Graph 1 shows network development for both experiments. The graph shows that network development in both networks is very fast during the first 1800 connections and then decelerates. Network development in the second experiment is slightly faster than in the first experiment for the first phases of network development, but reaches its asymptote sooner afterwards.
Graph 1: Network development expressed in QAP correlations with first network as a function of the number of selections in the network.
All learning rules operate in parallel and are expected to interact in the creation of new links and their consequent selection and reward by the browserâs choices. To analyze the learning rulesâ different contributions, we plotted the learning ruleâs rewards to the 20 strongest connections in the network from the second experiment. Six of these 20 connections have first been awarded by the symmetry or transitivity learning rule, then to be picked up by repeated rewards from the frequency learning. Due to the rather large interval of connections between subsequent measurements of network state, apparently Îsimultaneousâ onsets of rewards from all three learning rules could not be resolved into separately measured events, and so we expect this number to be even higher in reality. Graph 2 shows the rewards for the connections between the nodes Knowledge and Research and the connection between the Life and Nature nodes, as a function of the number of links that had been established in the network. Both connections have been introduced by either the symmetry or transitivity 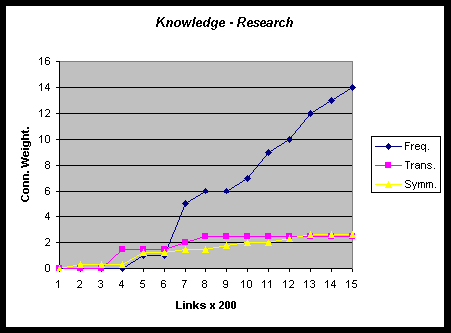
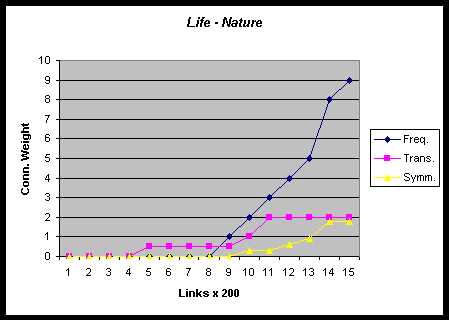 learning rule.
learning rule.
Graph 2: Contributions of different learning rules rewards for Knowledge-Research and Life-Nature connections as a function of number of selections in the network.
We performed an n-clique cluster analysis on the results from both experiments to gain insight into the general network structure. The cluster analysis revealed a remarkable structure of closely connected sets of nodes that seemed to be grouped according to their relation to highly general or abstract concepts such as "Time", "Space" and "Mind". Table 2 provides an overview of the 9 clusters that were found in the network structure resulting from the second experiment. Both networks contained highly similar clusters. In both cases the "cognition" cluster takes up about 33% of all words over all clusters, indicating its central position and importance in the network.
|
Cluste r |
Nodes |
|
Time |
Age, time, century, day, evening, moment, period, week, year |
|
Space |
Place, area, point, stage |
|
Movement |
Action, change, movement, road, car |
|
Control |
Authority, control, power, influence |
|
Cognition |
Knowledge, fact, idea, thought, interest, book, course, development, doubt, education, example, experience, language, mind, name, word, problem, question, reason, research, result, school, side, situation, story, theory, training, use, voice |
|
Intimacy |
Love, family, house, peace, father, friend, girl, hand, body, face, head, figure, heart, church, kind, mother, woman, music, bed, wife |
|
Vitality |
Boy, man, wife, health |
|
Society |
Society, state, town, commonwealth |
|
Office |
Building, office, work, room |
Table 2: Results of n-clique cluster analysis on network resulting from second experiment. Cluster names express intuitive descriptions of cluster content.
We also calculated the QAP-correlation between the two final networks to see how the differently developed networkâs structure corresponded. The calculated QAP correlation measured 0.58 after 4200 jumps. When symmetric closure was added to the first networkâs structure the QAP correlation measured 0.63. Both experiments thus resulted in reasonably similar networks.
These results indicate that network development was very fast and occurred mostly during the first phase of the networkâs development. In its first 1800 links both networks quickly achieved a relatively stable set of connections from most nodes. Afterwards only minor changes to the network structure took place in the form of small adjustments to the different ordering of links and connection weights.
The pattern in which a fast and vigorous development of network structure occurs during the first phases of the training process to then slow down to reach an asymptote can be explained by two factors. First, the rewards from the learning rules were set at constant values that were simply added to the connectionâs actual value. Connection strengths thus grew linearly larger with an increased number of selections and the rewards from the learning rules exerted continually less influence on the ordering of links in the network during the last phase of network development. This effect can account for the slow rate of change in network development after a certain number of selections. Second, the rapid restructuring of network structure during the initial phases of network development can be explained by a positive feedback loop that might be involved in the above described experimental set-up, and in fact the entire concept of a self-organizing network. As could be expected, subjects are more likely to select the items they read first in the list proposed to them. Therefore, connections that rise in the rank ordering because they are selected and rewarded would have a significantly higher probability of being selected on a following occasion. Thus, reinforcement of a link tends to produce further reinforcement. This feedback loop between link ordering and link selection might cause the high speed of network development during the first 1800 links. Feedback could have a beneficial effect on network development by strengthening new connections introduced by Symmetry and Transitivity in a fast loop of continuing rewards, administered by the Frequency learning rule. Any worthwhile link could as such rapidly achieve a high position, and pull transitively or symmetrically related links up in its wake. Our analysis of the different contributions of each learning rule to the 20 strongest connections in the second network (graph 2) and the analysis of network development speed (graph 1) seem to confirm this assumption.
At the end of each experiment, after some 6000 selections, the most frequented nodes had gathered a list of 10 strongest links that quite well reflected their direct semantic environment, with words that were near synonyms of the node name at the top of the list. However, this positive result was much less strong in the less frequented nodes, because of what we termed the "attractor effect". Nodes that had many incoming links, by accident, or because they were associated with many other words in the list, would tend to attract more users. This would result in increasing strength of their incoming paths, and their replacement by even stronger direct links. Especially in the first experiment, almost all paths would end up in a cluster of semantically related, strongly cross-linked nodes, forming an approximate attractor for the network (cf. Îcognitionâ-cluster in table 3). Although the random assignment of starting nodes meant that all nodes would be consulted on first entry with the same average frequency, the subsequent moves would very quickly end up in the attractor cluster. As a result, nodes outside the attractor would get little chance to learn and thus remained poorly connected.
In our second experiment, the introduction of the symmetry rule attenuated this effect, since strong links leading into an attractor would necessarily produce weaker, inverse links leading out of the attractor. This gave nodes outside the attractor the chance to develop some links of their own, generating new local attracting clusters, weakly connected to other clusters. The overall learning seemed more efficient in the sense that less time was needed to develop good associations, and the result was more balanced, in the sense that the differences in frequentation between nodes were less strong. The data shown in graph 1 as well as the cluster analysis of the networks seems to support this thesis. Although the learning algorithms only work on links and not on groups of nodes, it is remarkable how well the resulting clusters fit in with intuitive categories. This also seems to confirm that the set-up achieves its aim of absorbing the common semantics of a heterogeneous group of users.
The question however remained to what extent this system of adaptive hypertext succeeded in restructuring itself to ensure a maximal resemblance to the browsersâ shared mental models. The data from our first and second in situ experiment lacked any direct measurement of the browserâs mental models and we were thus not able to compare these to the final network structure. We therefore performed a number of simulations in which a programmed browser trained the adaptive hypertext networks rather than human subjects. This would enable us to train a sufficient number of networks to measure the statistical resemblance between the trained networks and the browserâs know mental model. To enable comparisons with the previous in situ experiments, we used the same networks and learning rules as have been outlined in the previous chapters.
To implement the artificial browser, we needed to plausibly simulate the behavior of goal-oriented browsers in hypertext. Therefore, the following plausible and computationally viable model of hypertext browsing was developed (3). It is based on the outlined analyses of the hypertext-browser system and the heuristic procedure known as hill-climbing (27). Hill climbing is a search heuristic that tries to locate a given functionâs global optimal values by always shifting position towards locally optimal values.
Let us assume that we can measure both user and mental model and represent them by matrices.
Then,
U, is the square, Boolean matrix of order n representing the user model (hypertext network structure), n being the number of pages in the network
M, is the square, integer matrix of order n that represents a subset of the browserâs preformed common knowledge of associations in general (20), applied to the nodes of network U, i.e. the browsers mental model.
Assume the browser has started browsing at position s in the network. The hyperlinks from this position can be found in Uâs row vector vs . If the browser is attempting to retrieve a certain node g in the network, then he will have to evaluate the values of vector vs according to how their selection will lead the browser closer to the desired position g. The values that shape this evaluation can be found in matrix Mâs column vector vg. This vectorâs values indicate the extent to which the browser feels a certain hyperlink will lead closer or farther from the desired goal-position.
If the values in both vectors, vg and vs are multiplied the resulting vector will indicate how instrumental a certain connection will be to move closer to the desired position in the network. The browser will then move to the position associated with this vectorâs maximal value from which the same evaluation will take place, and so on, until the goal position has been achieved.
The outlined model of associative hill climbing in hypertext has been implemented in an artificial browser agent that was used to independently browse and train adaptive hypertext networks . Lacking adequate data the artificial browserâs mental model was derived from the weighted average of the networks from our in situ experiment. The use of our data from the previous experiments seems to introduce circularity to the design. We are however not interested in the agentâs exact browsing behavior but rather the similarity between the browserâs known mental model and the resulting hypertext network structure. Any sufficiently structured mental would thus suit our purposes.
The Artificial Browser was programmed in C and ran on the universityâs IRIX system. The artificial browser trained 20 adaptive hypertext networks that were each browsed for 3000 connections.
Two interesting measurements could be derived from these results. The 20 networks had been trained by exactly the same browser using exactly the same mental model. Therefore any variations in the resulting network structure would be a product of the networkâs learning process. Two kinds of deviations could occur. First, the resulting networks could be unreliably related to the browserâs mental model. Unreliability in measurement occurs when for the same measured quantity a different measurement value occurs on different occasions. This bias is mostly due to random aberrations in the measuring apparatus. Second, even if the networks are reliably related to the browserâs mental models they can still be invalid due to constant biases in the measuring apparatus. The measurement is then said to be reliable but invalid; it measures constant, but wrong values.
Both reliability and validity of the adaptive hypertext system can be calculated from the networks that have been trained by the artificial browser. The amount to which the trained network correlate among each other is an indication of the stability of network development. Validity of network development on the other hand can be expressed by the correlation between the artificial browserâs known mental model and the final network structure.
The following QAP-correlations have thus been calculated.
Both calculated QAP-correlations thus indicate that development of hypertext networks is reliably and validly capable of resembling the browserâs mental model.
It was postulated that by insuring an as large as possible overlap between the network structure, i.e. the hypertext systemâs user model, and the browserâs mental model, hypertext networks could be made more efficient to browse for retrieval. The system for adaptive hypertext ensures this overlap and does so without any external system for explicit user categorizations and information filtering. The outlined system for the automated restructuring of hypertext networks has furthermore been shown to be a viable, efficient and reliable way of making hypertext networks adapt their structure to the userâs mental model.
The required overlap between network structure and mental model is a very plausible assertion. But even if the overlap between network structure and browserâs mental model is shown not be a very important factor in determining browsing efficiency, the present system will still have its benefits by automatically clustering related pages. This in itself might be an important contribution to the overall quality of hypertext network structure and browsing efficiency.
Although the system for adaptive hypertext applies a strictly local form of learning and requires no external storage of explicit user models or information filtering software, it can not be applied to the WWW as it is today. An implementation on the web would require a change to the HTTP protocol that enables servers to inform each other about where browsers are coming from and which connections to reward. Another difference with the experimental set-up is that Web documents typically contain texts or graphics and not just a list of linked nodes. Thus, users, when judging whether a document is interesting, will need more than the name or title provided by the link. A link that seems promising may well lead to a document with an irrelevant or useless content. Therefore, the learning mechanism should need some kind of "quality control". Possibly automated systems can check the content of documents that links point to, and inform the browser of the relevance of the page he/she is about to retrieve. Such enhancements require a more sophisticated exchange of messages between browser and server than provided by the present HTTP, but may lead to a much higher quality Web, without making additional demands on users and authors. The criticism that selecting links on the basis of frequent use will merely strengthen "conventional wisdom" or the "lowest common denominator", stifling creative, original or unpopular associations, is misdirected. First, the links made initially by the author of the document are not touched by the mechanism, and thus there is no restriction on introducing non-conformist associations. Second, the popularity of a link only matters relative to the other links "learned" by the same document. Specialized or controversial documents will normally only be consulted by a limited public interested in the specific subject of these documents. These users are not likely to suddenly jump to mainstream, popular subjects but will rather explore the pages that are relevant to the domain. As a group, they are likely to know more about the subject than the individual author, and are therefore likely to select relevant links unknown to that author. The system will in this case not force the lowest common denominator upon the designers of expert sites, but will rather improve them by combining the knowledge of several experts in the domain.
Bibliography.